Profil
Die Forschungsgruppe Data Science befasst sich mit allen Aspekten der Gewinnung, Verwaltung und Analyse von Informationen mit dem Ziel der Extraktion neuartigen Wissens. Ein besonderer Fokus liegt hierbei auf der Berücksichtigung neuartiger Informationsquellen aus dem Bereich Big Data wie beispielsweise User Generated Content (UGC) oder transaktionale Daten aus Social Media Plattformen, Location Tracking mittels mobiler Dienste oder Sensordaten beispielsweise aus IoT-Umgebungen. Im Einzelnen befasst sich die Forschungsgruppe mit folgenden Schwerpunkten.
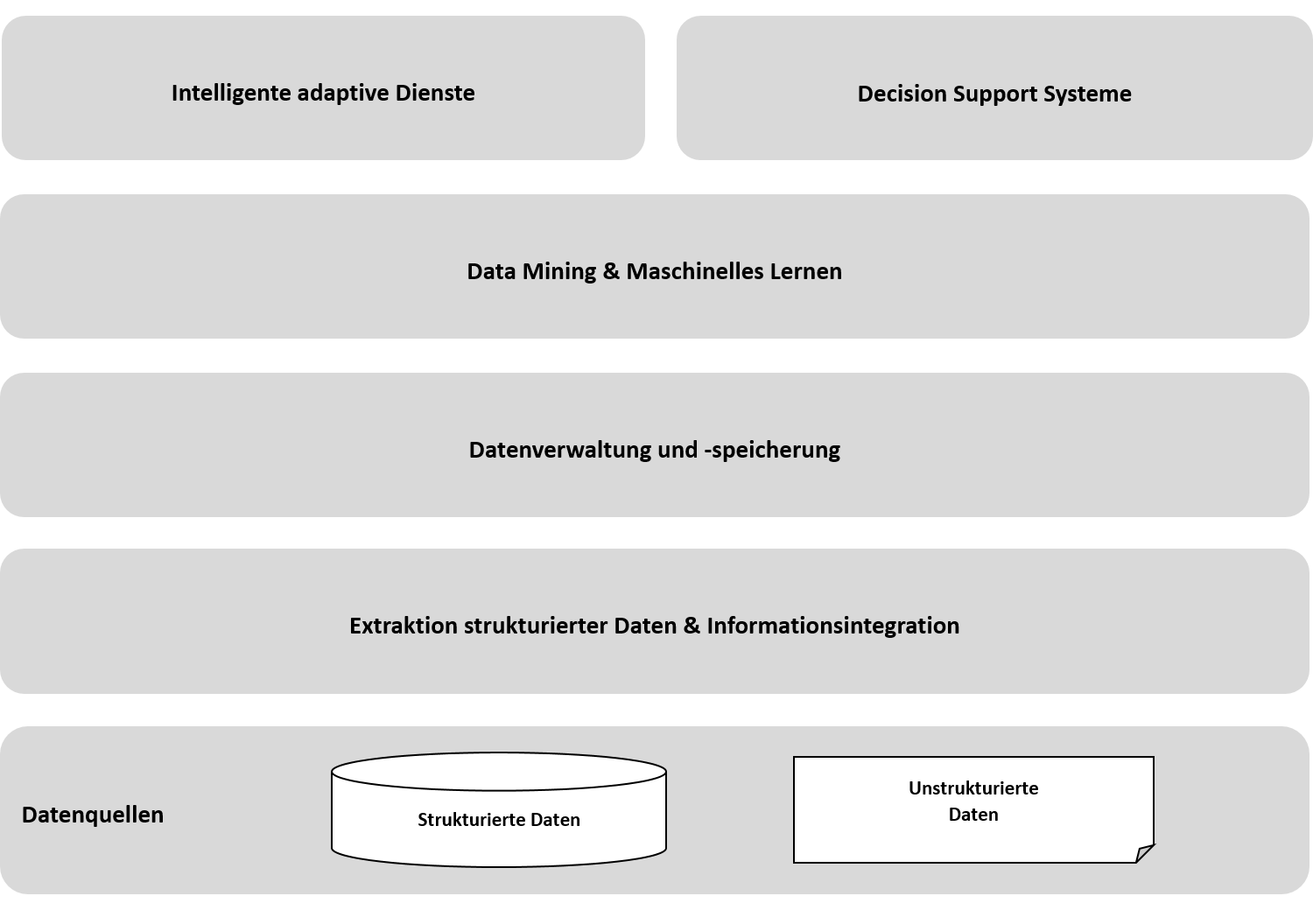
Extraktion strukturierter Daten & Informationsintegration
Extraktion strukturierter Daten aus unterschiedlichen Datenquellen und Datenformaten sowie intelligente Ansätze zur Integration heterogener Datenformate
- Datenextraktion aus operativen Systemen und Datenquellen (offline und online)
- Web Crawling & Wrapper-Induktion: Manuelle und (semi-)automatische Extraktion strukturierter Daten aus semi-strukturierten Datenformaten (z.B. html-Dateien)
- Datengenerierung mittels neuartiger Methoden, z.B. Sensoren, mobiler Endgeräte, etc.
- Integration heterogener Datenformate insb. auch mittels Semantic-Web-Technologien auf Basis domänenspezifischer Ontologien und Linked Open Data Ansätzen
Datenverwaltung und -speicherung
Datenhaltung unter Berücksichtigung unterschiedlicher Konzepte zum Umgang mit strukturierten und unstrukturierten Daten sowie großen Datenmengen und heterogenen Datenformaten
- Modellierung von Data Warehouse Strukturen (z.B. normalisierte vs. multi-dimensionale Modellierung)
- Flexible und leistungsstarke Konzepte der Datenverwaltung im Kontext von Big Data (NoSQL, Data Lakes, etc.)
- Knowledge Graphen und Graph-Datenbanken zur Bereitstellung semantisch annotierter Informationen
Data Mining & Maschinelles Lernen
Einsatz von Methoden des maschinellen Lernens zur Erkennung relevanter Muster und Trends und Generierung neuartigen Wissens
- Erprobung insb. auch neuartiger Verfahren des maschinellen Lernens zur Erkennung interessanter Muster und Trends (z.B. Verfahren des Deep Learning)
- Verwendung neuartiger Datenquellen (Big Data) zur Gewinnung neuer Erkenntnisse oder Verbesserung der Schätz- oder Prognosegenauigkeit
- Sentiment-Analyse und Opinion Mining mittels Methoden des Text Mining
- Bild- und Video-Analyse
Intelligente adaptive Dienste
Intelligente Adaptierung und Personalisierung von Diensten aufgrund vorliegender Informationen und Erkenntnisse
- Personalisierung von Angeboten und Recommender-Systeme
- Personalisierung und Adaptierung von Applikationen und Diensten (mobile Dienste, Online-Shops, Webseiten, etc.)
- Konversationale Systeme (insb. Recommender-Systeme) unter Berücksichtigung multi-modaler Nutzerschnittstellen (z.B. Freitexteingabe, Spracheingabe, usw.)
- Intelligente Dienste auf Basis von Knowledge Graphen (Ontology-Browsing, Semantic Reasoning)
Decision Support Systeme
Nutzung gewonnener Erkenntnisse als Input für die Entscheidungsunterstützung
- Adaptierung von Decision Support Systemen und Erprobung geeigneter Interfacemetaphern
- Integration von Data Mining Verfahren und Modellen in Decision Support Systeme
- Semantisches Maschinelles Lernen, d.h. Unterstützung der Interpretation der Ergebnisse des maschinellen Lernens auf Basis semantisch annotierter Daten (z.B. innerhalb eines Knowledge Graphen)
Projekte
Abgeschlossene Projekte
ANALYSE DER E-BIKE-NUTZUNG UND RADWEGINFRASTRUKTUR (NKI)
Das vom Bundesministerium für Umwelt, Naturschutz und Nukleare Sicherheit geförderte Projekt „NKI – Aufwertung der Radweginfrastruktur und Etablierung attraktiver umweltschonender…Kontakt & Personen
Allgemeine Kontaktinformationen
| Postadresse |
RWU Hochschule Ravensburg-Weingarten University of Applied Sciences Data Science Postfach 30 22
D 88216 Weingarten |
|---|
Mitglieder der Forschungsgruppe


