Ziel des Projekt ist eine zweitteilige Analyse eines Twitter-Datensatzes mit einer initiale Erkennung häufig genannter Themen durch eine Topic Detection mit anschließender Sentiment-Analyse anhand der gefundenen Themen.
Projektdurchführung
Oliver Dankwart
Forschungsgruppe Forschungsgruppe Data Science, Institut für Digitalen Wandel (IDW)
Einführung
- Soziale Netzwerke als essenzielle Treiber des modernen Internets und der Kommunikation
- Einfluss von Twitter-Beiträgen auf Unternehmen in Form von möglichen Kapitalverlusten und Branding-Einbußen
- Monitoring der sozialen Netzwerke durch automatische Analysen unter Anwendung von Methoden der Textanalyse wichtig für Unternehmen, um frühzeitig negative Beiträge zu moderieren
Zielsetzung
- Zweitteilige Analyse eines Twitter-Datensatzes zu Aktiengesellschaften aus der Technologie-Branche (GAFAM)
- Initiale Erkennung häufig genannter Themen durch eine Topic Detection mit folgender Sentiment-Analyse anhand der gefundenen Themen
- Grafische Aufbereitung mit anschließender Analyse der kombinierten Ergebnisse
Methodik
Datenaufbereitung
- Zusammenführen der Datenquellen (CSV-Dateien), Filterung auf Teildatensatz (Tweets aus 2019, nur Google & Co.) und Bereinigung der übrigen Datenzeilen
- Vorverarbeitung der Textdaten durch die Entfernung von Sonderzeichen (URLs, #, @-Nutzernamen, etc.), Tokenisierung, Part-of-Speech-Tagging, Lemmatisierung und Erzeugung des Bag of Words-Models
Topic Detection
- Anwendung des Latent Dirichlet Allocation-Algorithmus (LDA) zur Erkennung der Themen
- Optimierung des Topic-Modells anhand der Topic Anzahl K und Hyperparametern α und η unter Auswertung quantitativer Kennzahlen (Perplexity, Coherence-Metrik Cv)
Sentiment Analyse
- Lexikon-basierte Sentiment-Analyse mit Valence Aware Dictionary and Sentiment Reasoner (VADER-Algorithmus)
- Automatisches Einordnen der Twitter-Beiträge in Polaritäten positiv, negativ und neutral
Evaluierung der Ergebnisse
- Grafische Darstellung durch Zusammenführung der gefundenen Themen und den Häufigkeiten der Stimmungsrichtungen pro Thema
- Qualitative Auswertung durch manuelle Analyse und Nutzung des Analysetools pyLDAvis
Ergebnis
Ergebnisse der Topic Model-Optimierung
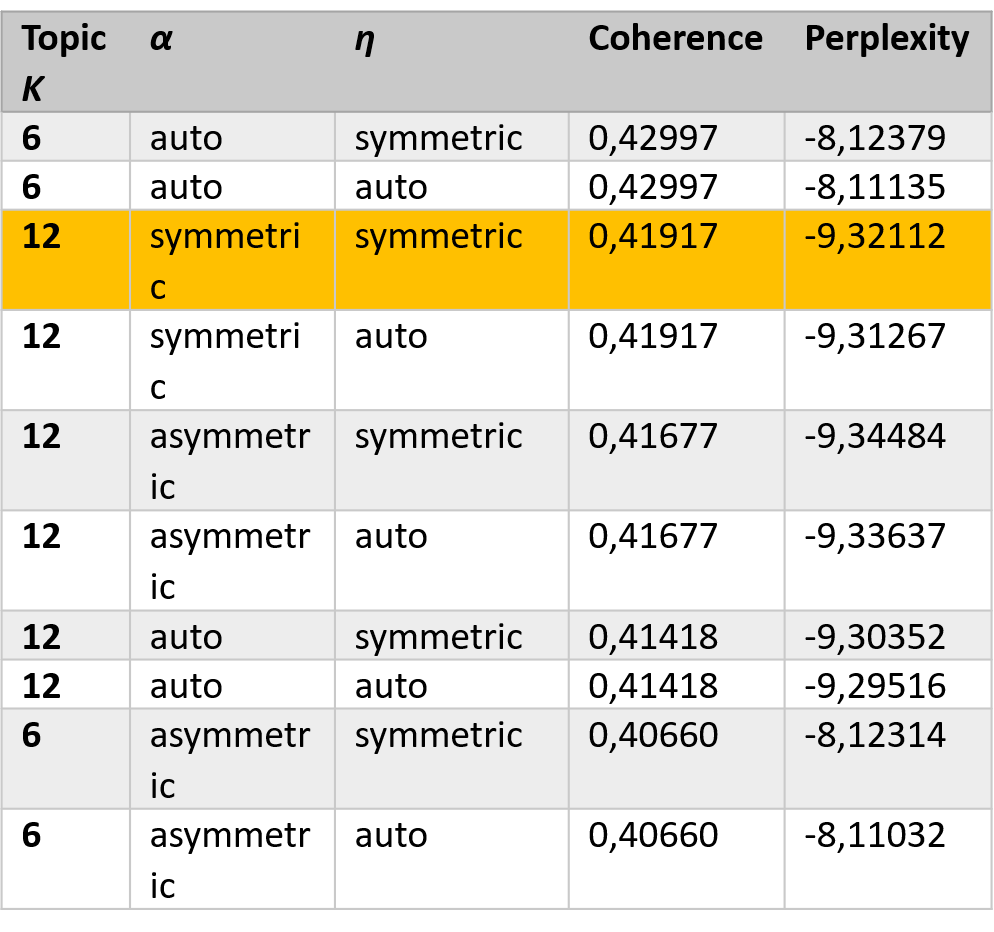
- Topic Anzahl 12 mit symmetrischem α und η führt zu bester Coherence/Perplexity-Kombination
Endergebnis Topic Detection & Sentiment Analyse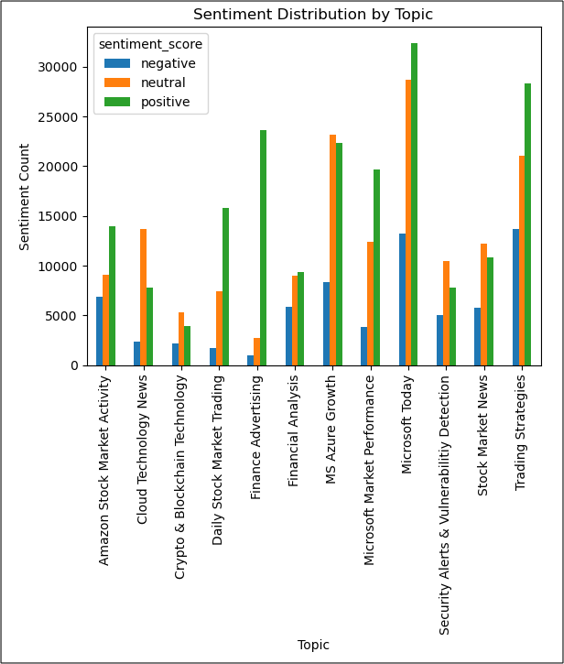
- Ergebnisse im Diagramm dienen der weiteren Praxisanwendung, bspw. Entscheidungsfindung in Unternehmen oder bei Finanzmarktakteuren
Ergebnisse Topic-Modell K=12
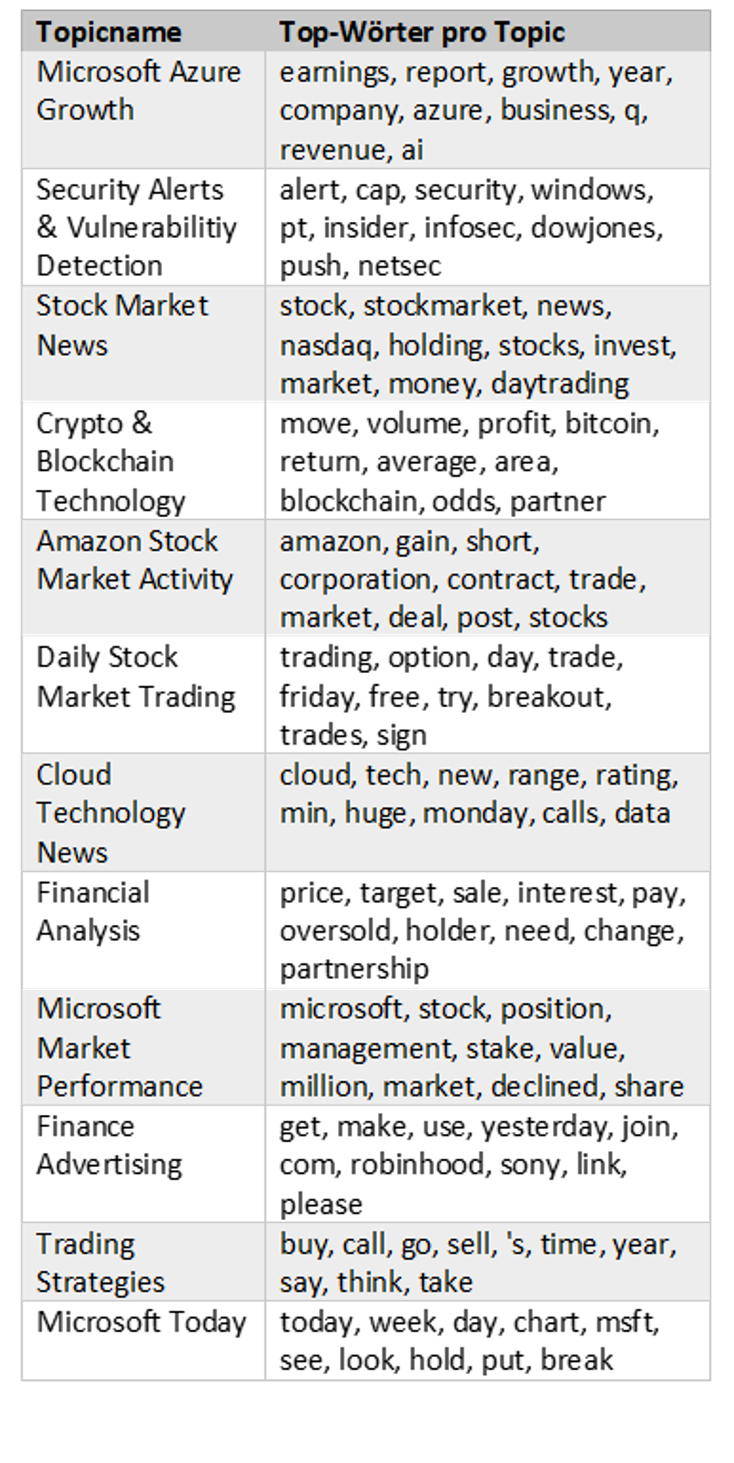
Zusammenfassung
- Optimierte Topic Detection erkennt relevante Themen in Social Media-Datensätzen
- Sentiment-Analyse verleiht Analyse eine weitere Dimension (Stimmung des Themas)
- Vielfältige Anwendungsmöglichkeiten der Ergebnisse bei Aktiengesellschaften, in der Finanzbranche selbst oder für Kleinanleger
Literatur
1. D. M. Blei, “Probabilistic Topic Models,” Commun. ACM, Jg. 55, Nr. 4, S. 77–84, Apr. 2012, issn: 0001-0782. doi: 10.1145/2133806.2133826. Adresse: https://doi.org/10.1145/2133806.2133826.
2. R. Churchill und L. Singh, “The Evolution of Topic Modeling,” S. 1–35, Nov. 2022. doi: 10.1145/3507900. Adresse: https://doi.org/10.1145/3507900
3. A. Giachanou und F. Crestani, “Like It or Not: A Survey of Twitter Sentiment Analysis Methods,” Bd. 49, Association for Computing Machinery, 2016. doi:10.1145/2938640. Adresse: https://doi.org/10.1145/2938640.